




有一款名为“网络天才VIP”的游戏,它属于西方文化背景下的休闲益智类型。游戏采用了浓郁的欧美卡通画风,搭配上富有动感的背景音乐,美漫风格贯穿始终,能让玩家在体验过程中产生强烈的沉浸感。游戏的主角是阿拉丁,玩家可以向这位天才提出问题,从中获取各类线索与提示,进而找到问题的答案。游戏的玩法设计大多较为简单,各个年龄段的玩家都能轻松上手游玩。
网络天才VIP拥有不同的游戏模式,玩家可以选择自己喜欢的模式进行挑战,赢取属于你的荣誉,创造更多的辉煌,快来体验一下吧。

1、使用账户功能,享受更多乐趣!
Akinator 想让您创建一个账号。您的 Aki奖励将会累计,您解锁的服装和 Geniz 金币也会同步。即使换了手机,这些记录都会同步。
2、寻找 Aki 奖
神秘猜谜伙伴邀你开启脑洞挑战,赢取珍贵等级徽章与专属荣誉席位。它热衷于各类角色谜题,更期待迎接高难度考验——你可以引导它尝试猜解那些尘封已久、鲜少被人提及的角色。快去看看排名榜单,向顶尖位置发起冲击吧!
3、成为头号玩家
挑战排行榜上其他玩家,看看究竟谁更厉害。你可以在最新的超级奖项或荣誉殿堂写上你的名字。
4、持续参与每日挑战
您可以每天找到五个神秘角色,来赢得额外或特殊的Aki 奖。完成全部的每日挑战来获取金额的每日 Aki 奖,这是最有声望的 Aki 奖!
5、释放您的创造力
您可以通过消耗Geniz点数来解锁并自定义心仪的Akinator形象。这位网络天才能化身为帝王、牛仔、音乐人等多种角色。借助12顶帽子与13件衣服,你可以创造出专属于自己的最有趣形象组合。
1、全球排行榜,玩家可以和全球的玩家共同冲击游戏中的排行榜,达到一定名词会获得相应的奖励。
2、有趣的每日任务系统,在这里所有玩家每天都会有着同样的每日任务。
3、游戏中人物的涉及度极广,无论是真实人物还是虚拟人物都能够被灯神才出来。
4、独特的陷阱模式,灯神在答出你心中所想的人物的时候会设置陷阱,你可要诚实作答才能得到灯神的奖励。
5、无止境地挑战:让他猜想谁是你的亲朋好友并把他们召集到你的myworld画廊中。
1、第一次进入游戏时需要选择语言,别担心游戏支持中文,之后点击创建账户;
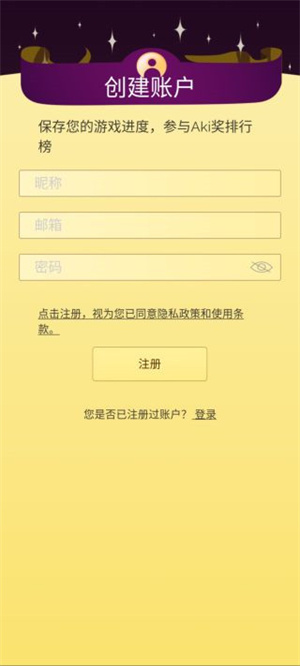
2、在注册界面,输入邮箱、密码以及昵称,之后点击注册;
3、在收到邮箱的激活提醒后,完成激活,之后再进入游戏;
4、注册完成,开始挑战灯神吧!

网络天才游戏怎么玩?大部分玩家还不知道该游戏具体的玩法,因此小编为大家带来了玩法教程,希望对大家有所帮助,一起来看看吧。
1、最初级的实现方法:关键词匹配
建一个关键词词库,对用户输入的语句进行关键词匹配,然后调用对应的知识库。
此种方式入门门槛很低,基本上是个程序员都能实现,例如现在微信公众平台的智能回复、诸多网站的敏感词过滤就是此类。
但此种方式存在诸多问题,例如:

a、由于是关键词匹配,如果用户输入的语句中出现多个关键词,此时由于涉及关键词权重(与知识库的关键词对比)等等问题,此时关键词匹配的方法就不擅长了
b、不存在对用户输入语句语义的理解,导致会出现答非所问的现象。当然在产品上对回答不上的问题就采用卖萌的方式来规避掉。
c、基本上无自学习能力,规则只能完全由人工维护,且规则基本是固定死的。
d、性能与扩展性欠佳。依旧以那句话包含多个关键词的情况为例,用常规程序语言进行关键词匹配,性能会非常差。就算运用一些文本处理算法(比如Double-array trie tree),也难以满足大规模场景的需求。
2、稍微高级点的实现方法:基于搜索引擎、文本挖掘、自然语言处理(NLP)等技术来实现
这种实现方式与单纯基于关键词匹配的模式不同,其核心目标在于通过分析简短文本(比如用户的提问语句)所传递的语义信息,精准判断用户的潜在意图,进而从规模庞大的知识库中筛选出关联度最高的内容。
具体技术实现就不细说了。举一个很粗糙的例子来简单说一下此种实现方法处理的思路(不严谨,只是为了说明思路)。
假如用户问:北京后天的温度是多少度?
如果采用纯搜索引擎的思路(基于文本挖掘、NLP的思路不尽相同,但可参考此思路),此时实际流程上分成几步处理:
1、对输入语句分词,得到北京、后天、温度3个关键词。分词时候利用了预先建好的行业词库,“北京”符合预先建好的城市库、“后天”符合日期库、“温度”符合气象库
2接下来,把分词处理后得到的内容与规则库通过特定算法进行匹配,找出匹配度最高的对应规则。假设规则库中存有一条关于天气查询的规则,其结构为城市信息集合、日期信息集合与气象信息集合的组合,借助这一规则就能初步判断用户或许是想了解某一地点在特定日期的天气情况。
3、对语义做具体解析,知道城市是北京,日期是后天,要获取的知识是天气预报
4、调用第三方的天气接口,例如中国天气网-专业天气预报、气象服务门户的数据
一、网络天才怎么玩?玩法原理
用户输入一段内容(并非局限于单个词语)→后端语义引擎对该输入内容展开语义层面的解析→推测出用户最具可能性的需求意图→调用与之对应的知识库、应用程序以及计算引擎→将处理后的结果反馈给用户。
二、答案怎么来的
最基础的实现途径是构建关键词词库,针对用户输入的语句开展关键词匹配操作,随后调用与之对应的知识库。这种方法的入门要求极低,几乎所有程序员都能够完成,像当前微信公众平台的智能回复功能、不少网站的敏感词过滤机制都属于这一类型。不过该方式也存在不少缺陷,比如:
a、由于是关键词匹配,如果用户输入的语句中出现多个关键词,此时由于涉及关键词权重(与知识库的关键词对比)等等问题,此时关键词匹配的方法就不擅长了。
b、不存在对用户输入语句语义的理解,导致会出现答非所问的现象。当然在产品上对回答不上的问题就采用卖萌的方式来规避掉。
c、基本上无自学习能力,规则只能完全由人工维护,且规则基本是固定死的。
这类方案在运行效率与规模适配方面存在短板。比如面对单句含多个检索目标的场景时,若用常规编程方式实现目标匹配,处理速度会显著下降;即便引入部分文本分析技术优化,也难以支撑高量级的应用场景需求。
AKINATAR网络天才游戏合集
网络天才游戏大全
十大休闲益智游戏推荐
好玩的休闲益智手游推荐





 namaiki
namaiki
 正太做梦模拟器Namaiki手机版
正太做梦模拟器Namaiki手机版
 97视频
97视频
 视频号助手
视频号助手
 千恋万花安卓汉化
千恋万花安卓汉化
 雷电将军的俘获生活30汉化版
雷电将军的俘获生活30汉化版
 密室调教2
密室调教2
 91影视
91影视
 黑料视频播放器
黑料视频播放器
 樱花校园模拟器中文版无广告
樱花校园模拟器中文版无广告




































